Co-authored-by: github-actions[bot] <github-actions[bot]@users.noreply.github.com> Co-authored-by: Claude Opus 4.7 <noreply@anthropic.com> Co-authored-by: rinfx <yucheng.lxr@alibaba-inc.com>
20 KiB
title, keywords, description
| title | keywords | description | |||
|---|---|---|---|---|---|
| AI内容安全 |
|
阿里云内容安全检测 |
功能说明
通过对接阿里云内容安全检测大模型的输入输出,保障AI应用内容合法合规。
运行属性
插件执行阶段:默认阶段
插件执行优先级:300
配置说明
| Name | Type | Requirement | Default | Description |
|---|---|---|---|---|
serviceName |
string | requried | - | 服务名 |
servicePort |
string | requried | - | 服务端口 |
serviceHost |
string | requried | - | 阿里云内容安全endpoint的域名 |
accessKey |
string | requried | - | 阿里云AK |
secretKey |
string | requried | - | 阿里云SK |
action |
string | requried | - | 阿里云ai安全业务接口 |
securityToken |
string | optional | - | 阿里云安全令牌(用于临时凭证) |
checkRequest |
bool | optional | false | 检查提问内容是否合规 |
checkResponse |
bool | optional | false | 检查大模型的回答内容是否合规,生效时会使流式响应变为非流式 |
requestCheckService |
string | optional | llm_query_moderation | 指定阿里云内容安全用于检测输入内容的服务 |
responseCheckService |
string | optional | llm_response_moderation | 指定阿里云内容安全用于检测输出内容的服务 |
requestContentJsonPath |
string | optional | messages.@reverse.0.content |
指定要检测内容在请求body中的jsonpath |
responseContentJsonPath |
string | optional | choices.0.message.content |
指定要检测内容在响应body中的jsonpath |
responseStreamContentJsonPath |
string | optional | choices.0.delta.content |
指定要检测内容在流式响应body中的jsonpath |
responseContentFallbackJsonPaths |
array | optional | [choices.0.message.content, content.#(type=="text")#.text] |
当 responseContentJsonPath 提取为空时,按顺序尝试这些兜底路径;与主路径相同的项会自动跳过;显式配置为空数组 [] 可禁用兜底 |
responseStreamContentFallbackJsonPaths |
array | optional | [choices.0.delta.content, delta.text] |
当 responseStreamContentJsonPath 提取为空时,按顺序尝试这些流式兜底路径;与主路径相同的项会自动跳过;显式配置为空数组 [] 可禁用兜底 |
denyCode |
int | optional | 200 | 指定内容非法时的响应状态码 |
denyMessage |
string | optional | openai格式的流式/非流式响应 | 指定内容非法时的响应内容 |
protocol |
string | optional | openai | 协议格式,非openai协议填original |
openAIDenyResponseFormat |
string | optional | legacy | OpenAI 包装拒答的响应形态,取值为 legacy 或 structured。默认 legacy 保持历史兼容;配置为 structured 时在 choices[0].x_higress_guardrail 输出结构化拦截详情 |
contentModerationLevelBar |
string | optional | max | 内容合规检测拦截风险等级,取值为 max, high, medium or low |
promptAttackLevelBar |
string | optional | max | 提示词攻击检测拦截风险等级,取值为 max, high, medium or low |
sensitiveDataLevelBar |
string | optional | S4 | 敏感内容检测拦截风险等级,取值为 S4, S3, S2 or S1 |
customLabelLevelBar |
string | optional | max | 自定义检测拦截风险等级,取值为 max, high, medium, low |
riskAction |
string | optional | block | 风险处置动作,取值为 block 或 mask。block 表示按风险等级阈值拦截请求,mask 表示当 API 返回脱敏建议时使用脱敏内容替换敏感字段。注意:脱敏功能仅适用于 MultiModalGuard 模式 |
timeout |
int | optional | 2000 | 调用内容安全服务时的超时时间 |
bufferLimit |
int | optional | 1000 | 调用内容安全服务时每段文本的长度限制 |
consumerRequestCheckService |
map | optional | - | 为不同消费者指定特定的请求检测服务 |
consumerResponseCheckService |
map | optional | - | 为不同消费者指定特定的响应检测服务 |
consumerRiskLevel |
map | optional | - | 为不同消费者指定各维度的拦截风险等级 |
拒绝响应结构
内容被拦截时,插件(MultiModalGuard action)会构造以下结构化 JSON 对象。protocol: original、MCP 与图像生成路径直接或间接返回该对象;OpenAI 文本生成包装路径默认保持历史兼容形态,只有配置 openAIDenyResponseFormat: structured 时才会把该对象嵌入到 OpenAI 响应中。
{
"code": 200,
"denyMessage": "很抱歉,我无法回答您的问题",
"blockedDetails": [
{
"type": "contentModeration",
"level": "high"
}
]
}
字段说明:
| 字段 | 类型 | 说明 |
|---|---|---|
code |
int | 在 text_generation(OpenAI 包装) 与 image_generation 路径下为网关返回的 HTTP 状态码,取自 denyCode(默认 200);在 protocol=original 与 mcp 路径下为安全服务返回的业务码(Response.Code,成功检测时为 200) |
denyMessage |
string | 人类可读拦截文案。OpenAI 包装路径下始终存在,取 denyMessage(默认 很抱歉,我无法回答您的问题);protocol=original / image_generation / mcp 路径下取 denyMessage,未配置时省略该字段(omitempty) |
blockedDetails |
array | 命中拦截的维度明细;若安全服务未返回 Detail,则根据顶层 RiskLevel/AttackLevel 自动合成。命中维度为空时返回 [] |
blockedDetails[].type |
string | 风险类型:contentModeration / promptAttack / sensitiveData / maliciousUrl / modelHallucination / customLabel |
blockedDetails[].level |
string | 风险等级:high / medium / low;敏感数据为 S1–S4 |
说明:当前实现的拒答 body 仅包含上述字段。不输出安全服务的
RequestId、单条Suggestion与原始业务码(guardCode);安全服务的RequestId通过 AI 日志safecheck_request_ids字段暴露(见下文 AI Log 章节)。
各协议承载位置:
text_generation(OpenAI,默认legacy):不输出x_higress_guardrail或历史x_higress字段;choices[0].message.content/ 首帧delta.content保持历史内容形态(RiskBlock 为 JSON 字符串,mask fallback 为拒答文案),finish_reason为"stop",流式响应仍以data: [DONE]结束text_generation(OpenAI,structured非流式):choices[0].message.content承载可读拦截文案(即denyMessage,未配置时默认为很抱歉,我无法回答您的问题);上述结构体作为嵌入对象放入choices[0].x_higress_guardrail(不是 JSON 字符串)text_generation(OpenAI,structured流式 SSE):首帧delta.content承载可读拦截文案;上述结构体仅在最后一个 chunk 中作为嵌入对象放入choices[0].x_higress_guardrail,随后以data: [DONE]结束流text_generation(protocol=original):上述结构体直接作为 JSON 响应 body 返回(不包 OpenAI 外壳,不新增x_higress_guardrail)image_generation:上述结构体直接作为 JSON 响应 body 返回(HTTP 403)mcp(JSON-RPC):上述结构体序列化为 JSON 字符串后放入error.messagemcp(SSE):同上,通过 SSE 事件返回
openAIDenyResponseFormat 只影响 OpenAI 包装拒答的 body 形态;拦截判断、fail-open 行为、metric 与 AI Log 字段不随该配置变化。该字段只能配置在插件全局,不能放入 consumerRiskLevel。
补充说明一下内容合规检测、提示词攻击检测、敏感内容检测三种风险的四个等级:
-
对于内容合规检测、提示词攻击检测:
max: 检测请求/响应内容,但是不会产生拦截行为high: 内容安全检测/提示词攻击检测 结果中风险等级为high时产生拦截medium: 内容安全检测/提示词攻击检测 结果中风险等级 >=medium时产生拦截low: 内容安全检测/提示词攻击检测 结果中风险等级 >=low时产生拦截
-
对于敏感内容检测:
S4: 检测请求/响应内容,但是不会产生拦截行为S3: 敏感内容检测结果中风险等级为S3时产生拦截S2: 敏感内容检测结果中风险等级 >=S2时产生拦截S1: 敏感内容检测结果中风险等级 >=S1时产生拦截
-
对于自定义检测(customLabel):
max: 检测请求/响应内容,但是不会产生拦截行为high: 自定义检测结果中风险等级为high时产生拦截- 注意:阿里云 API 对 customLabel 维度仅返回
high和none两个等级,不同于其他维度的四级划分。配置为high即可在检测命中时拦截,配置为max则不拦截。medium和low为配置兼容性保留,但 API 不会返回这些等级。
-
对于风险处置动作(riskAction):
block: 按各维度的风险等级阈值判断是否拦截mask: 当 API 返回Suggestion=mask时使用脱敏内容替换敏感字段,当Suggestion=block时仍会拦截- 注意:脱敏功能仅适用于 MultiModalGuard 模式(action 配置为 MultiModalGuard),其他模式不支持脱敏
配置示例
前提条件
由于插件中需要调用阿里云内容安全服务,所以需要先创建一个DNS类型的服务,例如:
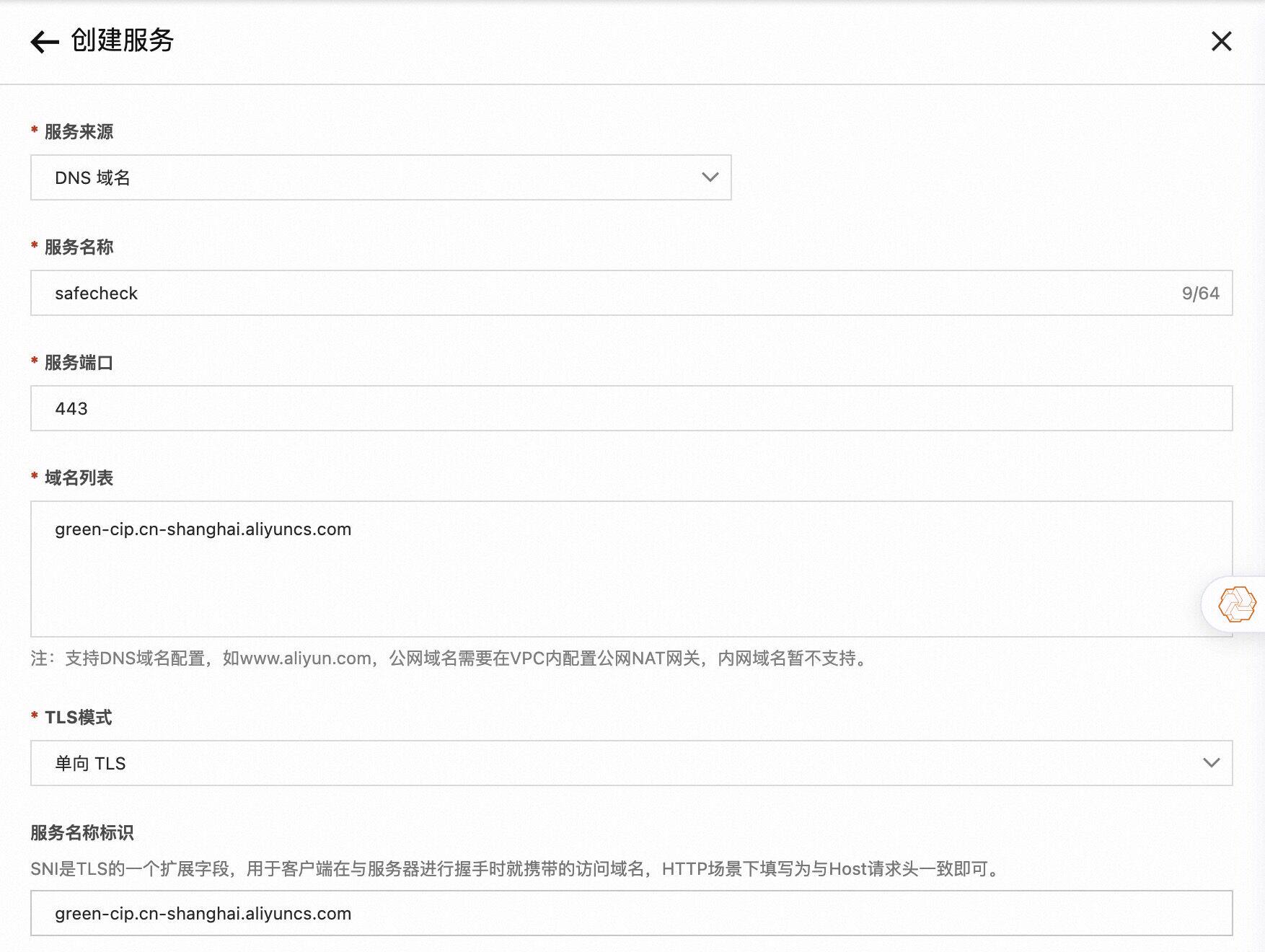
阿里云内容安全配置示例:
requestCheckService: llm_query_moderation
responseCheckService: llm_response_moderation
阿里云AI安全护栏配置示例:
requestCheckService: query_security_check
responseCheckService: response_security_check
检测输入内容是否合规
serviceName: safecheck.dns
servicePort: 443
serviceHost: "green-cip.cn-shanghai.aliyuncs.com"
accessKey: "XXXXXXXXX"
secretKey: "XXXXXXXXXXXXXXX"
checkRequest: true
检测输入与输出是否合规
serviceName: safecheck.dns
servicePort: 443
serviceHost: green-cip.cn-shanghai.aliyuncs.com
accessKey: "XXXXXXXXX"
secretKey: "XXXXXXXXXXXXXXX"
checkRequest: true
checkResponse: true
配置 OpenAI 结构化拒答
默认 openAIDenyResponseFormat: legacy 保持历史响应形态。若需要在 OpenAI 响应中输出结构化拦截详情,可配置:
openAIDenyResponseFormat: structured
使用临时安全凭证
serviceName: safecheck.dns
servicePort: 443
serviceHost: "green-cip.cn-shanghai.aliyuncs.com"
accessKey: "XXXXXXXXX"
secretKey: "XXXXXXXXXXXXXXX"
securityToken: "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
checkRequest: true
为不同消费者指定不同的检测服务
serviceName: safecheck.dns
servicePort: 443
serviceHost: "green-cip.cn-shanghai.aliyuncs.com"
accessKey: "XXXXXXXXX"
secretKey: "XXXXXXXXXXXXXXX"
checkRequest: true
consumerSpecificRequestCheckService:
consumerA: llm_query_moderation_strict
consumerB: llm_query_moderation_relaxed
consumerSpecificResponseCheckService:
consumerA: llm_response_moderation_strict
consumerB: llm_response_moderation_relaxed
指定自定义内容安全检测服务
用户可能需要根据不同的场景配置不同的检测规则,该问题可通过为不同域名/路由/服务配置不同的内容安全检测服务实现。如下图所示,我们创建了一个名为 llm_query_moderation_01 的检测服务,其中的检测规则在 llm_query_moderation 之上做了一些改动:
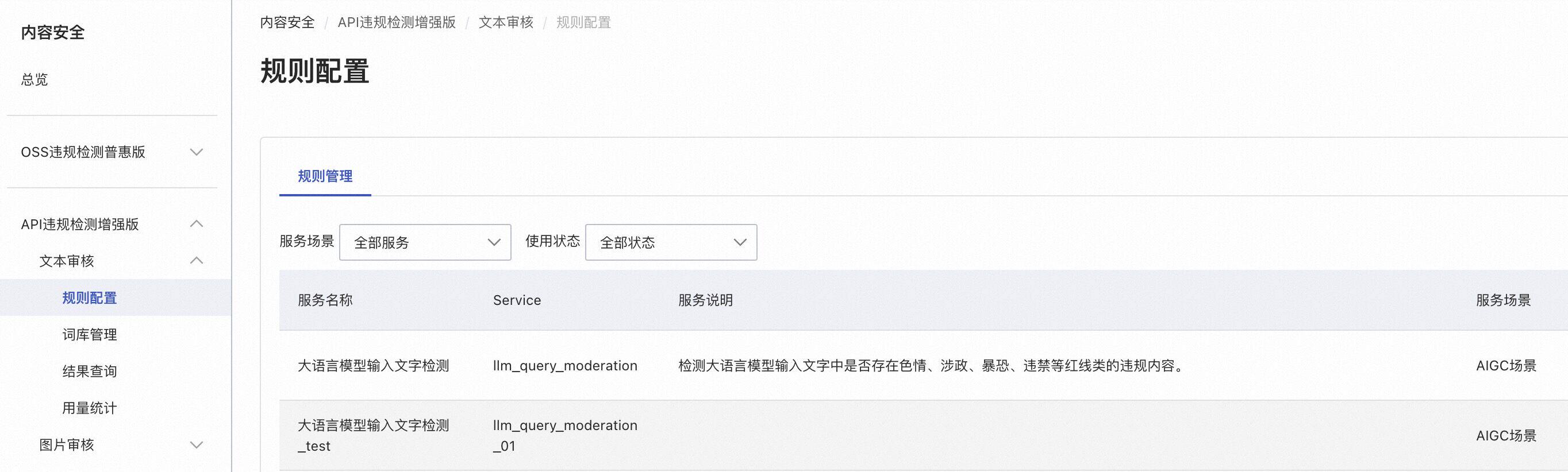
接下来在目标域名/路由/服务级别进行以下配置,指定使用我们自定义的 llm_query_moderation_01 中的规则进行检测:
serviceName: safecheck.dns
servicePort: 443
serviceHost: "green-cip.cn-shanghai.aliyuncs.com"
accessKey: "XXXXXXXXX"
secretKey: "XXXXXXXXXXXXXXX"
checkRequest: true
requestCheckService: llm_query_moderation_01
配置非openai协议(例如百炼App)
serviceName: safecheck.dns
servicePort: 443
serviceHost: "green-cip.cn-shanghai.aliyuncs.com"
accessKey: "XXXXXXXXX"
secretKey: "XXXXXXXXXXXXXXX"
checkRequest: true
checkResponse: true
requestContentJsonPath: "input.prompt"
responseContentJsonPath: "output.text"
denyCode: 200
denyMessage: "很抱歉,我无法回答您的问题"
protocol: original
配置响应内容兜底提取路径
当主路径提取不到内容时,可按优先级顺序配置兜底路径,兼容多种返回协议:
serviceName: safecheck.dns
servicePort: 443
serviceHost: "green-cip.cn-shanghai.aliyuncs.com"
accessKey: "XXXXXXXXX"
secretKey: "XXXXXXXXXXXXXXX"
checkResponse: true
responseContentJsonPath: "choices.0.message.content"
responseStreamContentJsonPath: "choices.0.delta.content"
responseContentFallbackJsonPaths:
- "output.text"
- 'content.#(type=="text")#.text'
responseStreamContentFallbackJsonPaths:
- "payload.delta"
- "delta.text"
如需严格模式(主路径未命中即跳过,不走兜底),可显式关闭兜底:
responseContentFallbackJsonPaths: []
responseStreamContentFallbackJsonPaths: []
可观测
Metric
ai-security-guard 插件提供了以下监控指标:
ai_sec_request_deny: 请求内容安全检测失败请求数ai_sec_response_deny: 模型回答安全检测失败请求数
图像响应阶段 metric/ai_log 字段重命名(过渡期)
历史上图像生成插件(lvwang/multi_modal_guard/image/openai.go、lvwang/multi_modal_guard/image/qwen.go)在响应阶段命中风险时错误地写入了请求阶段字段。本次版本修正了语义,并在 1~2 个发版周期内保留双写过渡:
| 行为 | 旧值(错误,将在后续版本移除) | 新值(推荐) |
|---|---|---|
| 计数器(deny) | ai_sec_request_deny |
ai_sec_response_deny |
| ai_log 耗时(pass + deny) | safecheck_request_rt |
safecheck_response_rt |
| ai_log 状态(deny) | safecheck_status="reqeust deny"(典型拼写错误,本次直接废弃,不再写入) |
safecheck_status="response deny" |
过渡期内图像响应阶段会同时写入新旧两组 *_deny 计数器和 safecheck_*_rt 字段;safecheck_status 只写新值。看板与告警请尽快切换到 response_* 字段名;当前依赖 reqeust deny(拼写错误版本)状态串的图像响应告警需要立即改为 response deny。
Trace
如果开启了链路追踪,ai-security-guard 插件会在请求 span 中添加以下 attributes:
ai_sec_risklabel: 表示请求命中的风险类型ai_sec_deny_phase: 表示请求被检测到风险的阶段(取值为request或者response)
AI Log
ai-security-guard 插件会将每次提交给内容安全服务的检测结果写入 AI 访问日志,用于将网关日志和阿里云内容安全请求关联起来:
| 字段 | 类型 | 说明 |
|---|---|---|
safecheck_requests |
array | 检测提交事件数组,每个元素为 {"requestId"?: string, "phase": string, "modality": string, "result": string} |
safecheck_request_ids |
array | 当前网关请求内所有有效内容安全 RequestId,按提交完成顺序保留,不去重、不截断 |
safecheck_request_id |
string | 最新一个有效内容安全 RequestId,用于兼容只读取单值的日志消费方 |
safecheck_status |
string | 历史兼容字段,反映本次网关请求最后一次状态变更的语义(详见下方枚举) |
safecheck_request_rt / safecheck_response_rt |
int | 请求/响应阶段安全检测的耗时(毫秒) |
safecheck_riskLabel / safecheck_riskWords |
string | 命中风险时的风险标签与风险词(取自安全服务返回的第一个命中结果) |
safecheck_requests[].phase 取值为 request 或 response;modality 取值为 text、image 或 mcp;result 表示该次提交事件本身的处理结果(而非网关最终对外动作),取值与含义如下:
result 取值 |
含义 |
|---|---|
pass |
该次提交检测通过 |
deny |
该次提交命中风险,网关已对外返回拒答 |
mask |
该次提交命中风险且 Action=Mask,安全服务返回了脱敏文本并用于改写请求体 |
error |
该次提交本身处理失败(HTTP 非 200、业务 Code 非 200、反序列化失败、构造拒答响应失败、调用内容安全服务失败等)。错误发生在响应阶段流式回调且原因是构造拒答响应失败时,网关会 fail-open(直接放行上游缓冲内容),此时 safecheck_status=build_fallback_pass,对应事件 result=error 表示这次安全提交未完成 |
只有安全服务响应中的 RequestId 是 JSON 字符串且 strings.TrimSpace(RequestId) != "" 时,才会写入 requestId、safecheck_request_ids 和 safecheck_request_id;缺失、空字符串、空白字符串或非字符串值不会写入空占位。
每一次提交尝试都会生成一个 safecheck_requests 事件,包括 HTTP 非 200、业务失败码以及调用内容安全服务失败等错误场景,错误结果会记录为 result=error。需要精确审计多次提交、流式分段或图片多次检测时,应优先使用 safecheck_requests。
safecheck_status 枚举(历史字段,按"最后一次状态变更"覆盖,存在多次提交时仅保留最后一次的语义):
safecheck_status 取值 |
含义 |
|---|---|
request pass |
请求阶段所有提交均通过 |
request mask |
请求阶段命中 mask,请求体已被脱敏文本改写 |
reqeust deny |
请求阶段命中风险,网关返回拒答(注:拼写为 reqeust,沿用历史,保持向后兼容) |
request error |
请求阶段安全提交本身失败(HTTP/反序列化/调用安全服务等),网关 fail-open 放行 |
response pass |
响应阶段所有提交均通过 |
response deny |
响应阶段命中风险,网关返回拒答 |
response error |
响应阶段安全提交本身失败,网关 fail-open 放行 |
build_fallback_pass |
响应阶段流式回调里构造拒答响应失败,网关 fail-open 直接放行上游缓冲内容 |
请求示例
curl http://localhost/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "这是一段非法内容"
}
]
}'
当配置 openAIDenyResponseFormat: structured 时,请求内容会被发送到阿里云内容安全服务进行检测。如果请求内容检测结果为非法,网关将返回形如以下的回答:
{
"id": "chatcmpl-AAy3hK1dE4ODaegbGOMoC9VY4Sizv",
"object": "chat.completion",
"created": 1727078400,
"model": "from-security-guard",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "作为一名人工智能助手,我不能提供涉及色情、暴力、政治等敏感话题的内容。如果您有其他相关问题,欢迎您提问。"
},
"logprobs": null,
"finish_reason": "stop",
"x_higress_guardrail": {
"code": 200,
"denyMessage": "作为一名人工智能助手,我不能提供涉及色情、暴力、政治等敏感话题的内容。如果您有其他相关问题,欢迎您提问。",
"blockedDetails": [
{
"type": "contentModeration",
"level": "high"
}
]
}
}
],
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
}
}