mirror of
https://github.com/NanmiCoder/MediaCrawler.git
synced 2026-06-08 02:47:26 +08:00
feat: 小红书笔记搜索,评论获取done
docs: update docs Create .gitattributes Update README.md
This commit is contained in:
37
README.md
Normal file
37
README.md
Normal file
@@ -0,0 +1,37 @@
|
||||
> **!!免责声明:!!**
|
||||
|
||||
> 本仓库的所有内容仅供学习和参考之用,禁止用于商业用途。任何人或组织不得将本仓库的内容用于非法用途或侵犯他人合法权益。本仓库所涉及的爬虫技术仅用于学习和研究,不得用于对其他平台进行大规模爬虫或其他非法行为。对于因使用本仓库内容而引起的任何法律责任,本仓库不承担任何责任。使用本仓库的内容即表示您同意本免责声明的所有条款和条件。
|
||||
|
||||
# 仓库描述
|
||||
这个代码仓库是一个利用[playwright](https://playwright.dev/)的爬虫程序
|
||||
可以准确地爬取小红书、抖音的笔记、评论等信息,大概原理是:利用playwright登录成功后,保留登录成功后的上下文浏览器环境,通过上下文浏览器环境执行JS表达式获取一些加密参数,再使用python的httpx发起异步请求,相当于使用Playwright搭桥,免去了复现核心加密JS代码,逆向难度大大降低。
|
||||
|
||||
|
||||
## 主要功能
|
||||
|
||||
- [x] 爬取小红书笔记、评论
|
||||
- [ ] To do 爬取抖音视频、评论
|
||||
|
||||
## 技术栈
|
||||
|
||||
- playwright
|
||||
- httpx
|
||||
- Web逆向
|
||||
|
||||
## 使用方法
|
||||
|
||||
1. 安装依赖库
|
||||
`pip install -r requirements.txt`
|
||||
2. 安装playwright浏览器驱动
|
||||
`playwright install`
|
||||
3. 运行爬虫程序
|
||||
`python main.py --platform xhs --keywords 健身`
|
||||
4. 打开小红书扫二维码登录
|
||||
|
||||
## 运行截图
|
||||
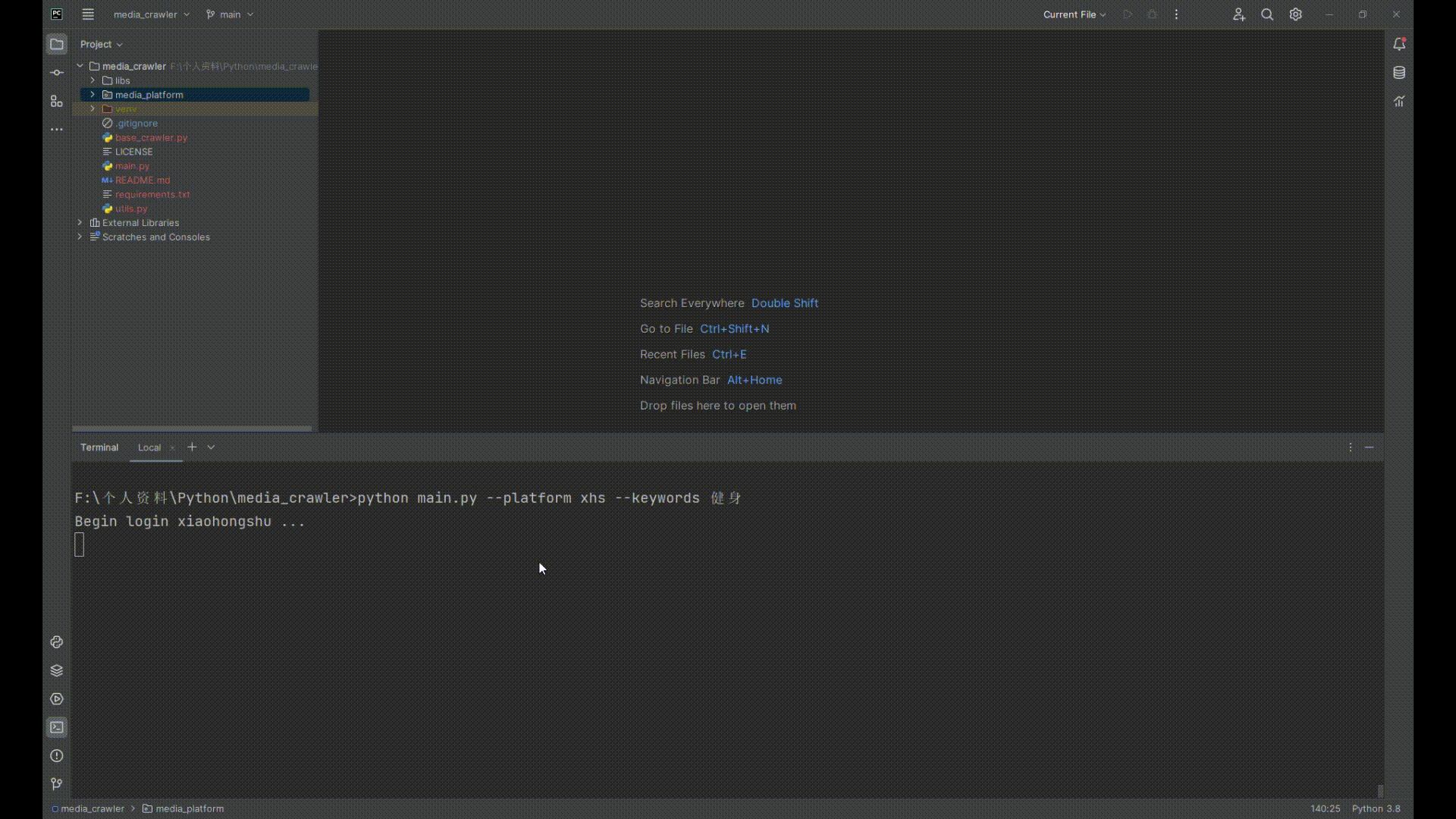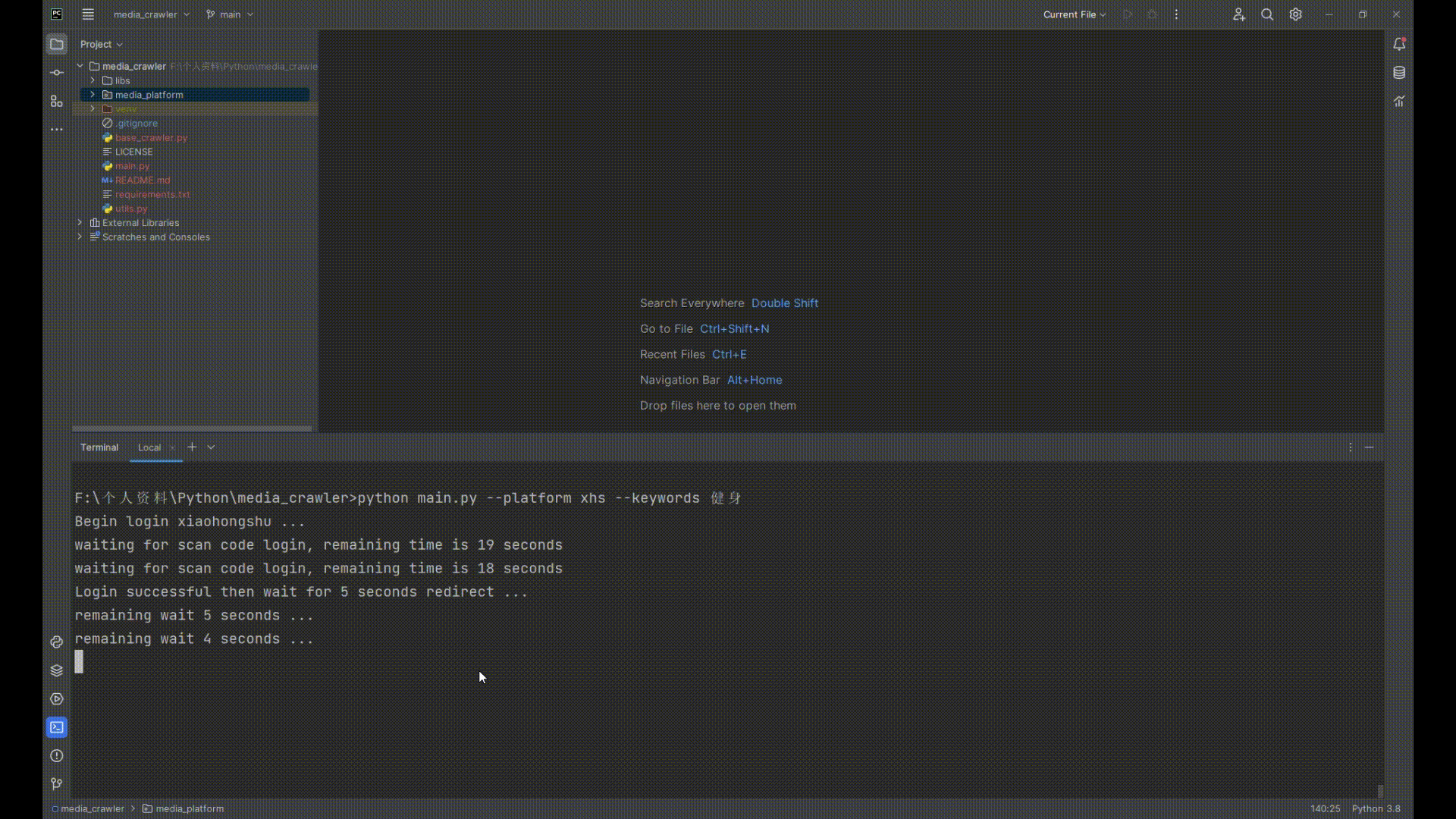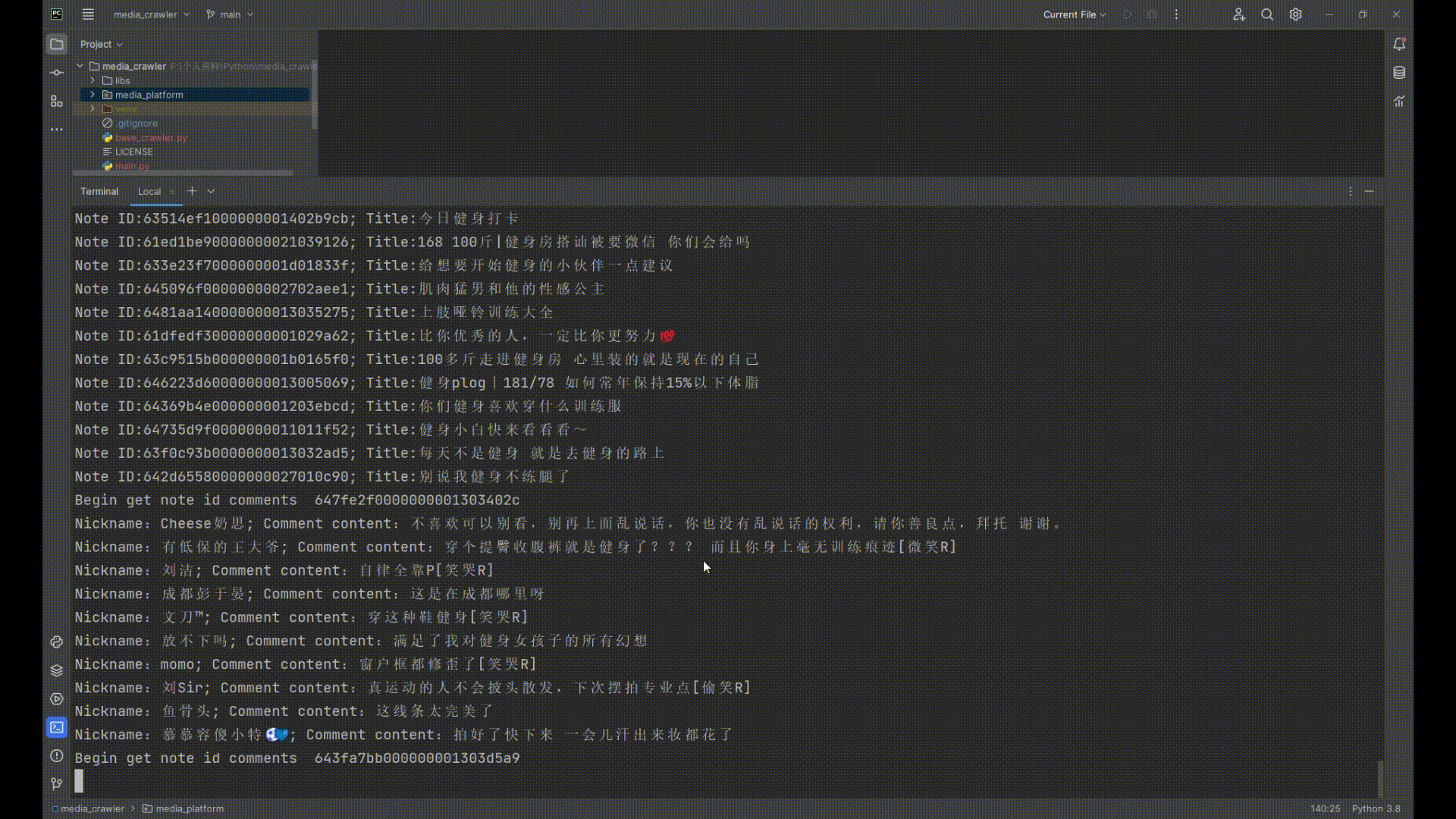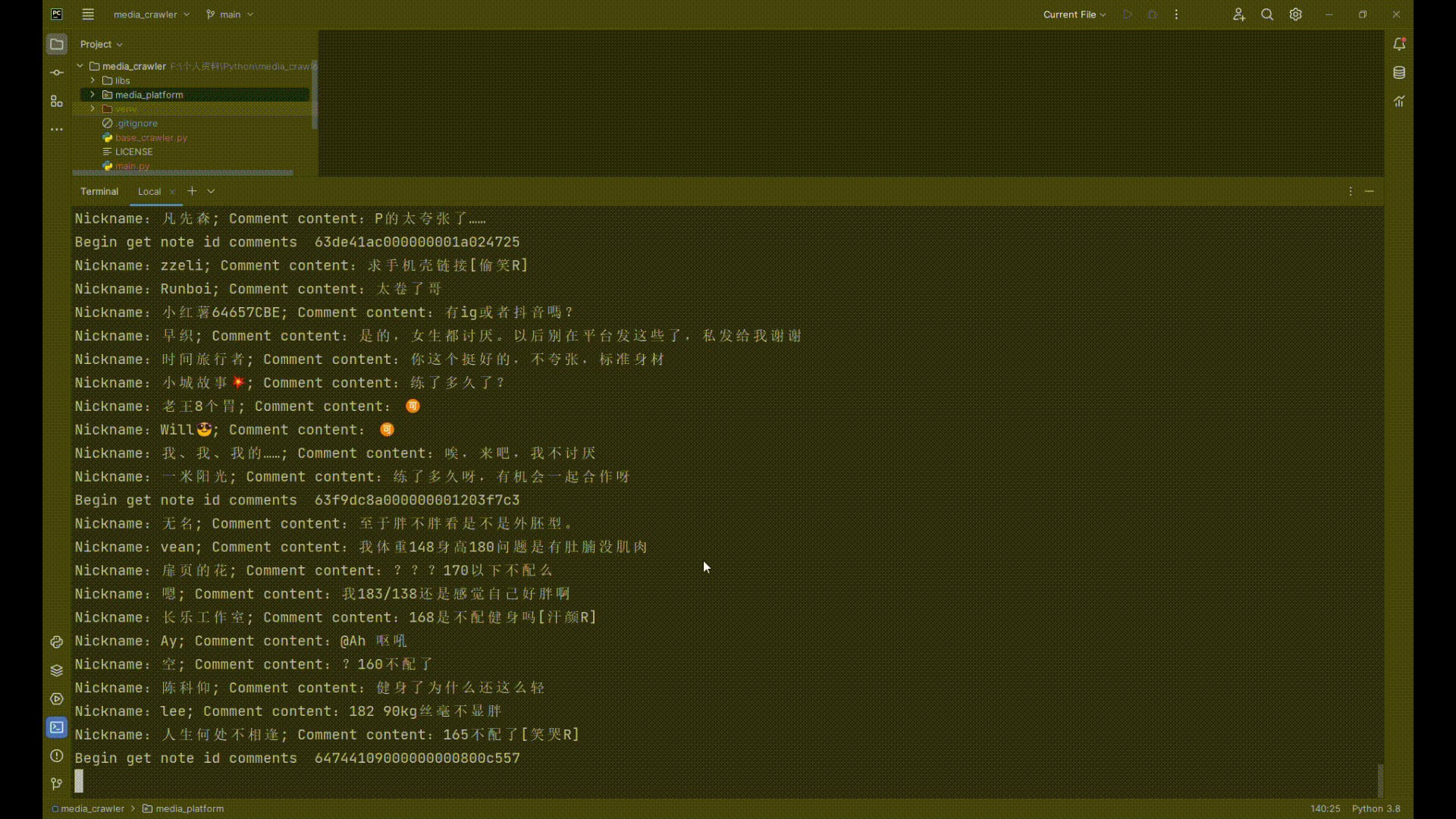
|
||||
|
||||
## 参考
|
||||
本仓库中小红书代码部分来自[ReaJason的xhs仓库](https://github.com/ReaJason/xhs),感谢ReaJason
|
||||
|
||||
|
||||
Reference in New Issue
Block a user